NIH. Not invented here. In software development, this means a preference for in-house code. People have strong feelings about this, but let’s try to ground ourselves in some actual analysis. When does it make sense?
A third-party dependency is code you don’t have to write, but it introduces risk. Some people say “if you can replace a dependency with an afternoon of coding, do it!”.
Is that right? Let’s ask xkcd.
Here is a favorite, often-cited graphic on automation from xkcd/1205:
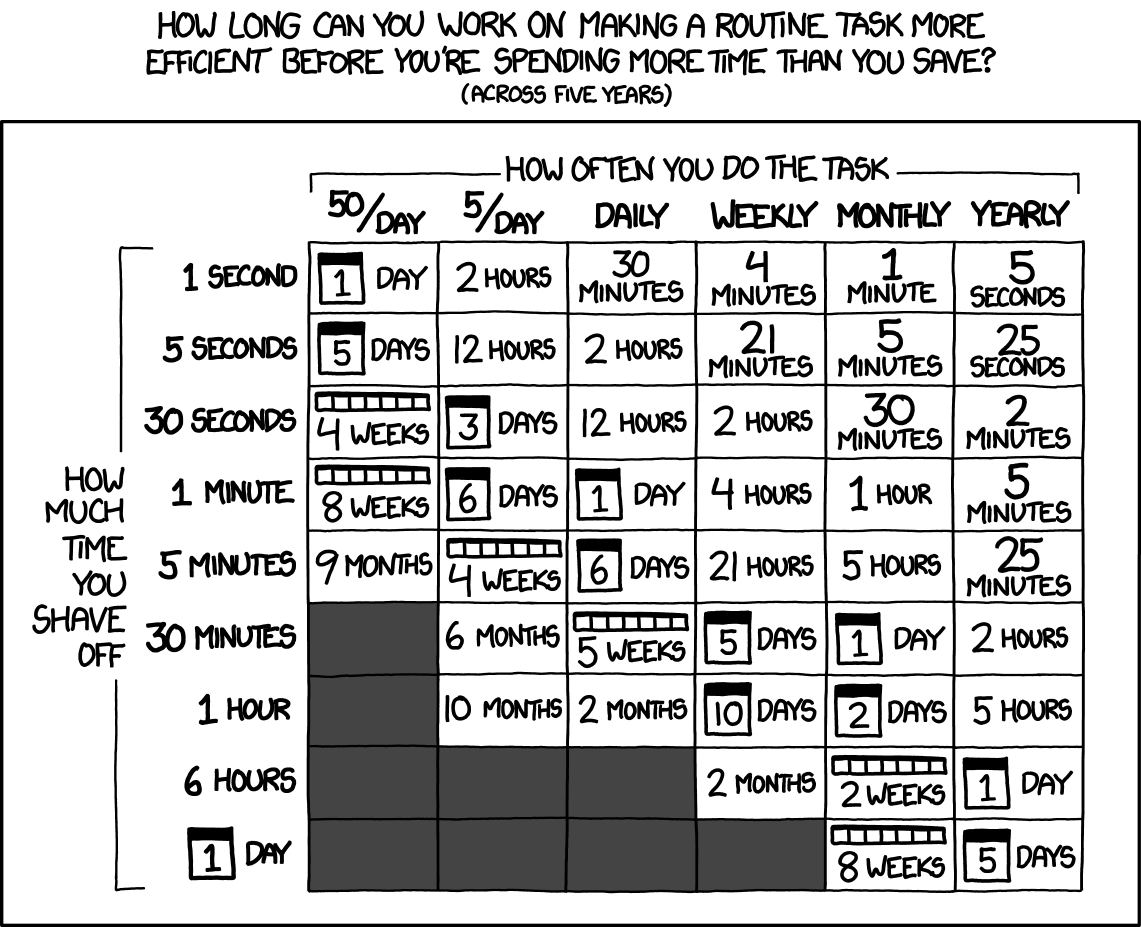
The table tells you how long you should spend to automate a task based on how often you do the task and how much time automation saves you.
This also works for thinking about code dependencies.
Assume that our time horizon is five years, like in xkcd. Except, we’ll make these changes:
- ‘how often you do the task’ → ‘how often will the dependency break?’
- ‘how much time you shave off’ → ‘how long will it take to fix?’
Let’s assume a dependency breaks on you once a year. Let’s assume it takes half a day to write a workaround, test it, code review it, and deploy. Looking at the ‘yearly’ column and the ‘6 hours’ row, that tells us that we should spend at most one day writing a replacement.
Of course, this conclusion assumes you write perfect code that won’t need to be touched again for five years. (Isn’t all your code like that?)
The real world can’t be so simple, right?
The alternative to taking an external dependency is to build your own replacement. There’s a cost to build it and because we don’t usually write perfect code, there’s a risk that it will break and an associated cost to that, just like with a dependency.
A replacement only makes (economic) sense if the cost of failures in the replacement is less than the cost of failures in the dependency.
If so, then there is ‘budget’ for writing the replacement.
Understanding the difference in failure costs – and thus the ‘budget’ for a replacement – requires comparing the dependency and replacement along two dimensions:
- How often do failures happen?
- How much does it cost when they do?
Most people jusifiably focus on the first as it’s the easiest to affect. If you can reduce the failure rate enough, then spending days on a replacement is easy to justify. But there are cases where failure cost matters, particularly if a replacement is faster to deploy.
Assessing risk of failures 🔗︎
First, we’re probably overestimating the risk of a dependency. And that might skew whether we think a replacement can do better.
Cognitive biases are mental heuristics to give rapid decisions in the face of uncertainty. They’re great for keeping humanity alive in a hostile world. They’re also known to introduce severe and systematic errors. Two are particularly relevant:
-
Availability bias – weighting recent or memorable experiences more heavily.
-
Confirmation bias – selectively considering evidence to support a preconception.
We remember most clearly the times that dependencies blew up on us, when they exasperated us, and they form the set of cases that we think about when we assess how likely a dependency is to fail.
Many projects of any size have dependencies and transitive dependencies in the dozens or hundreds. We forget how many dependencies just work and we discount them from our assessment of the likelihood of a dependency going bad on us.
That leads to considering a ‘portfolio’ effect. The more dependencies we have, the more likely that we’ll experience a problem with a dependency in any given period of time. In other words, the odds that some dependency will be a problem are much higher than the odds of any particular dependency being a problem.
So when we’re deciding on the risk of failure of a dependency – and whether we can do better – we need to be honest in our assessment of the risk of that particular dependency, not dependencies in general.
Next, we need to answer this question: what gives us any confidence that the code we’d write to avoid a dependency is any better than the dependency? Or what would lead us to the opposite conclusion? Here are some factors worth considering:
- complexity of the business domain
- dependency project team and activity
- scope of use
- size and complexity of the codebase
Some domains are relatively simple and others are fiendishly complex. For example, string padding is simple. On the other side, we have topics like time-zone-aware date math, Unicode collation algorithms, SOAP, the 13 RFCs that define the rules for MIME, and so on.
The simpler the topic, the more confidence we might have that the replacement will be at least no worse than the dependency. The more complex the topic, the more skeptical we should be. We need to ask ourselves honestly whether we have specialized knowledge that’s better than the maintainers of the dependency.
ESR said in The Cathedral and the Bazaar that “given enough eyeballs, all bugs are shallow”. A popular, active dependency project, with many users and multiple contributors, should be more reliable than one with a single maintainer, few users, or a long list of unaddressed issues and open pull requests. Will the replacement have more eyeballs than the dependency? If a replacement will be used by a lot of internal teams, it’s going to have more eyes on it than if it’s used by just one team.
However, these questions might not have the same weight if we don’t need everything a dependency is offering us. If our scope is a tiny subset of the full feature set, then the complexity of reimplementing that subset might be less than the whole. How much of a dependency do we really need?
If we assume that bug density per line of code will be relatively comparable between a replacement and a dependency, then one way that a replacement might arrive at a lower failure rate is by having a lot less code. Less code usually means less complexity as well, making finding and fixing problems easier. Can the replacement be a lot smaller and simpler than the dependency it replaces?
To sum up, if want replacement reliability to be better than dependency reliability, we should look for cases where some or all of the following are true:
- The business domain is simple
- The dependency is not widely used or is poorly maintained
- The replacement can implement a subset of features with smaller, simpler code.
Assessing cost of failures 🔗︎
When comparing cost of failure, we need to focus on two things: the time to fix the failure and the time to deploy the fix.
Why just focus on time factors? Because the actual incident cost of the downtime, error, or whatever, is going to be the same for a dependency or a replacement. The only thing that differs is how long things take.
The time to fix a bug should be relatively similar for a dependency and a replacement. In both cases, a problem has to be replicated and diagnosed. In my experience, that’s the hard part of most bugs – the actual fixes are usually simpler.
That might not be true if the dependency is in a different language. If the dependency is a C library and the application isn’t C or C++, then a replacement in the project language might be faster to fix because of engineer fluency in the project language and tooling.
It’s easier to imagine a difference in deploy time between a dependency and a replacement. Can our dependency manager trivially swap in a local fork of deep dependency? If so, then we’re insulated from a dependency maintainer that is slow to fix bugs, apply pull requests and release new versions. In a sense, it’s a free option to shift from a dependency to a replacement on demand.
If we can’t deploy an updated dependency or a local patch quickly, we’re in trouble if the ongong incident cost of failure is also high. Perhaps our dependency manager isn’t sufficient. Maybe we’re in a regulated environment where updates to dependency require a security review. These situations lean towards a replacement over a dependency.
Bringing it all together 🔗︎
Should you write a replacement or not?
Again, you need to have a good theory for why a replacement will have a lower failure rate than a dependency. It a simple thing? Will it have less code?
If you don’t see an advantage in failure rate, do you have a theory for better time to fix and deploy? If not, just stop. You’re done. Use the dependency.
Assuming the long-term economics favor a replacement solution, only then is it time to figure out the acceptable build cost. To approximate that, we can go back to an xkcd-style matrix. But we need to make two changes: a longer timeframe and a larger range of costs.

From thinking about risk assessment and the portfolio effect, we know that failure rate for any single dependency will be lower, so this chart goes out to five years.
For cost of a failure, we can reduce everything down to the number of engineer-days to fix and deploy. Make sure to consider the cost of the downtime until the fix is deployed! (An incident that costs $2,000 a day in lost revenue is comparable to the cost of an extra engineer to work the problem.)
Then we compare the position on the chart for the dependency and the replacement. If the time factors are comparable, then the cost factors are similar and you’ll be on one row of the chart. Find the column for the replacement and the column for the dependency, then the difference will be the number of engineer-days you can afford to build the replacement. If you can build your own in that time budget and deliver the decreased failure rate, then do it!
But we can generalize further from patterns in the chart since the accuracy of our estimates is probably poor anyway:
If the cost is small, it’s probably worth spending half-a-day to a day.
If the cost is big, it’s probably worth spending days to weeks.
But only if you’re sure you can reduce the failure rate!
[As I was writing this article, xkcd released a new comic called, appropriately, Dependency.]