tl;dr: I led hours of “consensus discussions” about toolchain governance, the Test::Builder roadmap, PAUSE policies and responsible authoring practices. I fixed bugs and applied patches for CPAN.pm, CPAN indexing and CPAN META tools. I experimented with indexing META files to generate deep reverse-dependency graphs. I concluded I need to invent Metabase 3.0.
Why I love the Perl QA Hackathon 🔗︎
I noticed my last several write-ups started with a “why I love…” section. I thought about doing something different, but realized that it really is the most important thing I want to say each year.
The Perl QA Hackathon is the one time during the year when I get to set aside concentrated time to scratch my itches about the Perl ecosystem – things that have been bugging all year that I just haven’t had a chance to work on.
Most of the attendees are people I only talk to online the rest of the year. I love getting to see people face to face, share a meal, tell some jokes, and connect as people and not just as fellow programmers.
This isn’t the kind of hackathon where caffeine-abusing participants race to churn out hip, shiny, disposable apps to wow a crowd or a future employer. This is more like Scotty and his team getting that long-overdue layover at a starbase to give the weary Enterprise an overhaul from the inside-out.

It’s dirty, gory work… and a lot of fun!
How the Perl community benefits 🔗︎
It’s often said that CPAN is Perl’s killer feature. But for anyone who’s worked with Perl for a while, it’s obvious that CPAN comes with a lot of sharp edges.
The Perl QA Hackathon brings together some of the top people working on smoothing out those sharp edges and gives them some dedicated time to think about, discuss, implement and deploy solutions. Everyone benefits!
The hackathon is broad, with proposed projects covering dependency hell, repeatable deployments, testing libraries, code quality analysis, build systems, continuous integration tools and more. We fix security holes, chase down edge conditions and stubborn bugs, debate new standards, and review long dormant pull requests.
Day -1 🔗︎
On Tuesday, I arrived at Berlin’s Tegel airport at what my body clock insisted was 2AM after a grand total of 2 hours of sleep. This was probably my personal low point of the hackathon; I hate red-eye flights. Also on my flight were Ricardo Signes, Tatsuhiko Miyagawa, and Matt and Dom Horsfall.

Fortunately, we arrived to a beautiful, warm spring day! As we were too early to check into the hotel, Ricardo, Matt, Dom and I dropped our bags and went out wandering to explore Berlin.


Lunch that day was bratwurst, my first of the trip, which I might have enjoyed more if I weren’t feeling hung-over from the flight.
After getting into the hotel, showering and napping, I met everyone for dinner at a local pub that became the “go to” place across the street from the hackathon.
Day 0 🔗︎
Wednesday had the best weather of the conference – almost early summer weather – and several of us took full advantage to hit some typical tourist spots within walking distance of the hotel.



After lunch and another nap I worked a bit on planning the agenda for the various “consensus” discussions I was moderating for the next few days. At that point, my red-eye hangover had faded (though I wouldn’t sleep well the whole trip) and I felt ready to get started.
That evening was the welcome dinner for all the participants. I wound up at a table with Peter Rabbitson, and we “amused” ourselves with a heated debate over what it meant to be a responsible maintainer – a theme to which we would return repeatedly, and more peaceably, for the next many days.
Day 1 🔗︎
Thursday was our first day in the Betahaus space.

I kicked off the day moderating the first 2-ish hour large-group discussion, this one on the Test-Simple roadmap.
Test-Simple roadmap 🔗︎
I wanted to start with the Test-Simple roadmap discussion to give Chad Granum (the current maintainer) some direction for the rest of his time at the hackathon. As the reason for this talk may be a bit opaque to my readers, I’ll step back and provide some context:
Test-Simple is the name of the standard testing library distribution. In addition to the familiar Test::More module, it has Test::Builder, which is the underlying framework that powers most of the test libraries on CPAN.
Over the last year, Chad has been working on a major internal refactoring of Test::Builder. Last October, an alpha was merged to the Perl blead branch for testing, but, due to ongoing concerns, was reverted out of blead in March.
One of my goals for the hackathon was to get broad consensus on a roadmap for it: would it eventually go forward as a new Test::Builder or should it be released as a “Test::Builder2”? If it were to go forward, what had to be done to assuage critics that it was ready?
In the discussion, I asked people to step back from the implementation and consider Test::Builder itself. Were the problems in it sufficient to justify reworking its guts? The group agreed on several unavoidable problems with the current design:
- Async/multi-process support is either non-existent or requires complex and fragile work-arounds.
- The lack of extension points has led many test libraries to invade the private internals of the Test::Builder singleton, or to monkey-patch its methods. These hacks are inherently fragile and the more the test ecosystem proliferates such things, the more likelihood that mixing arbitrary test libraries will break in unexpected ways.
- Testing test libraries requires either parsing TAP or checking against specific strings. This is hard, leaving many test libraries poorly tested, if at all. When there are tests, the tests are fragile. Overall, this limits the ability of test library authors to evolve TAP itself.
- More generally, having the test library so tightly coupled to TAP means that the capabilities of the library are limited to what TAP supports and there’s no easy way to use the standard testing library, but output results in a different form (e.g. xUnit-style).
In addition, the current Test::Builder was judged to be heavy and slow, holding too much state and doing to much repetitive work.
With broad consensus to move forward with a rewrite to address these concerns, we had Chad walk us through the architectural design of his alpha releases. After a bit of discussion about why concerns were separated the way they were, the group agreed the design was reasonable and turned to how to evaluate the specifics of the implementation.
After yet more debate about how best to assess readiness, we converged on a “punch list” of items to be completed before we considered the new implementation ready to be released as the stable Test::Builder:
- A single Test-Simple branch with proposed code and a corresponding Test-Simple dev release to CPAN (Chad)
- Single document describing all known issues (Chad to write; Andreas to review)
- Invite people to install latest dev in their daily perls for feedback
- Write document explaining how to do so and how to roll-back (Chad and Ricardo)
- Update CPAN delta smokes: compare test results for all of CPAN with latest Test-Simple stable and latest dev (Andreas, Leon, David)
- On Perl versions 5.8.1 and 5.20.2; both with and without threads
- Finding no new changes from previous list of incompatible modules doing unsupported things
- Line-by-line review of
$Test::Builder::Levelback compatibility support (Peter to review; David to vet results) - bleadperl delta smoke with verbose harness output with latest stable and latest dev; review line-by-line diff (Chad and Karen)
- Should be no substantive changes (outside Test-Simple tests themselves)
- Performance benchmarking — while specific workloads will vary, generally a ~15% slowdown on a “typical” workload is acceptable if it delivers the other desired benefits.
- Add patches to existing benchmarking tools in Test-Simple repo (Karen and bulk88)
- Run benchmarks on at least Linux (Chad) and Windows (volunteer needed)
I was very pleased that we got convergence on a roadmap. While not everyone that participated was comfortable with the idea of moving the redesign forward, no one had any other concrete ideas for a punch list.
PAUSE and CPAN clients 🔗︎
I spent most of the rest of my day on PAUSE and CPAN.pm related issues.
Andreas merged and made live my long-awaited pull request to improve the detail available in email reports when the PAUSE indexer fails to index a distribution. I immediately whipped up a distribution designed to fail and sent it through to test the change.
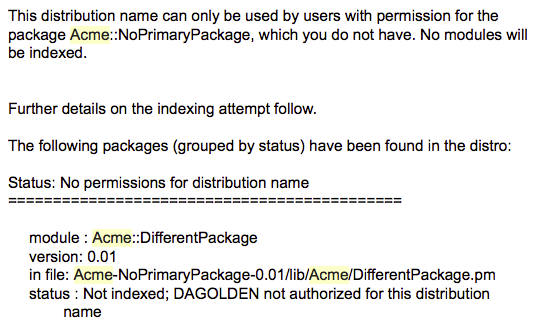
I then spent some time diagnosing problems with CPAN.pm bootstrapping local::lib on perls from 5.14 to 5.18. I finally tracked it down to some internal changes in local::lib and filed a hack-ish pull-request that would restore support in legacy CPAN.pm clients.
Meanwhile, Miyagawa had fired off several pull-requests to enhance CPAN::Common::Index and then wanted to discuss more invasive changes to support a MetaCPAN backend for it.
Aftermath 🔗︎
We had another group dinner that night, but I was pretty wiped and headed back early to the hotel for a little more quiet hacking in the hotel.
Before crashing, I dusting off various CPAN Testers libraries that I hadn’t looked at in years, updating a couple of them to my new Dist::Zilla-based build setup.
Day 2 🔗︎


On Friday, I largely split my time between analytics on META files and discussion moderation.
Indexing CPAN Meta 🔗︎
Since I had volunteered to help regression test Test::Builder, I decided to experiment with indexing META files to find dependent distributions. I keep a minicpan on my hard drive, so I used CPAN::Visitor to unpack all the META files and stick them into a local MongoDB database for analysis.
I had been thinking about doing that anyway as a demonstration for my MongoDB and Perl talk at YAPC::NA, so this gave me a chance to try it out and see if it was feasible. My initial test run was about 40 minutes — cutting it too close for a talk — though I kept iterating over the course of the hackathon and got it substantially faster by the time I got home.
To develop the candidates for regression testing, I decided to rule out most modules using Test::More in the way it was intended — that API wasn’t changing. Instead, I decided to look at three different sets of distributions:
- Distributions with either
$Test::Builder::LevelorTest::Builder->method calls in the codebase. I found these via http://grep.cpan.me/, using the App::cpangrep tool. - Distributions with modules that start with “Test::”. While not all use Test::Builder, most do.
- Distributions that depend on the “Test::” modules above. In case those modules don’t have good tests, testing their dependents should exercise them well.
The result, after various munging and de-duplicating, came out to just over 6000 distributions to regression test. I’d done similar tests before with Module::Build, so I dug up my old regression test tools to see if they might still be useful.
Toolchain governance and PAUSE adoption policies 🔗︎
In the middle of the day, I took a break to lead another 2-hour group discussion. I’ll be writing these up in much greater detail separately, so I’ll only mention the topics in general:
- Would toolchain authors agree to a “toolchain charter” governing how modules can be managed more as a group and less as a loose collection of individuals?
- What principles and practices would the group agree to?
- How should toolchain modules get handed off over time when maintainers disappear or need to take a break?
We then had a related discussion about how PAUSE module hand-overs should work. Currently, the PAUSE adoption process hands over a module to any interested party after the primary maintainer has been non-responsive for a period of time. While that seemed fine for a rarely used module, on reflection it didn’t seem right as modules have more and more dependents.
I’ll say more about that in the discussion write-up I’ll post separately, but in general, the consensus view was that PAUSE admins need to exercise more judgment in adoption approvals and that for a widely used module, an prospective adopter needs to make a case for stewardship.
Day 3 🔗︎

On Saturday, I focused my morning on coding and scheduled that day’s consensus discussions in the late afternoon so we’d have to end before our social outing to Berlin’s computer game museum.
Hacking on CPAN Meta modules 🔗︎
I applied a bunch of pull requests to CPAN::Meta and CPAN::Meta::Requirements, some from the hackathon and some from before. One of the most significant was Karen Etheridge’s patch to CPAN::Meta::Merge to allow deep merging of non-conflicting keys.
I shipped dev releases of both to CPAN so they could get smoked by CPAN Testers before I release them as stable. This was a practice that I’ve committed to adopting as part of the toolchain governance discussions. Even if I don’t think there are any changes that will break on a platform, I’d rather be safe and test a dev release than ship to CPAN and break it.
Improved CPAN.pm warnings for missing make 🔗︎
While playing with some virtual machines generously donated by DreamHost for our regression testing, I found myself struggling to bootstrap local::lib with CPAN.pm. I initially thought it was the same problem I’d had on Tuesday, but after flailing a while, I realized my mistake.
Always install the ‘build-essential’ (or equivalent) package on a new machine!
I’ve made that mistake before and just forgot about it. Unfortunately, CPAN.pm doesn’t tell you that make isn’t installed; it just tells you it failed.
So I quickly sent a pull request to Andreas to fix that and it will be in the next release of CPAN.pm.
Revived Metabase::Web 🔗︎
Metabase::Web is the code that runs the service that receives CPAN Testers reports. I haven’t touched it in years and spent some time getting familiar again with how to configure and launch a Catalyst app.
One of my near-to-medium term goals is to get CPAN Testers off Amazon SimpleDB (because it’s horrible and expensive). I had already been looking at MongoDB as a replacement even before I joined MongoDB because the document storage model fits well. Now that I work for MongoDB, I have both extra incentive and company support for spending some time on it.
I got Metabase::Web working using my experimental MongoDB backend I wrote years ago and was able to send CPAN Testers reports to a Metabase running locally with a local MongoDB.
Consensus discussions, technical 🔗︎
By Saturday, I was feeling a bit fried from discussion moderations, so for that day’s discussions, I focused it on pretty concrete technical decisions, rather than broad culture/governance issues.
These included on questions around the evolution of the CPAN Meta Spec, changes to CPAN Testers grading, signaling a desire for pure-Perl builds to compiler detection tools, and some PAUSE policies or lack thereof.
For the most part, decisions came quickly and I’ll be including them in more detail in my subsequent write up.
Computer Game Museum 🔗︎
I intentionally scheduled the consensus discussions with a hard stop time for those of us visiting Berlin’s Computerspiele Museum

Visiting the museum was like a traveling through time and visiting my childhood. They had many of the computers, consoles and games I remembered from when I was a kid. And of course, some of the exhibits were playable!


One of the more memorable exhibits in the museum was a rather bizarre game – essentially Pong, but where each player had to keep a hand on a pad that alternatively shocked, scorched, or whipped the player’s hand. The first person to take their hand off the pad lost. Several people in our group left with bruises from playing.


I played only once and did not lose. :-)
Day 4 🔗︎
On Sunday we had the most important discussion of the hackathon, one that will probably have a significant impact on how I work as a CPAN author. In my other time, I tied up a lot more loose ends and started thinking about how to build a regression tester.
Responsible author practices and responsible forking 🔗︎
Neil Bowers and Peter Ribasushi came up with a very evocative analogy for CPAN and Neil presented it to the group to kick off our discussions.
To paraphrase, consider CPAN like a river, where a distribution’s position in the river depends on total number of other “downstream” distributions that depend on it — i.e. dependents plus dependents of dependents plus dependents of those, etc. until there are no more dependents to count.
A distribution that has no dependents is all the way downstream. By contrast, most of the CPAN toolchain is all the way upstream. A broken module upstream causes cascading failures all the way down the river. See Neil’s blog post, The River of CPAN, for more.
That suggests that the standards for “responsible authorship” are different at different points in the river. An experimental module I throw over the wall to CPAN needs a lot less care than something I wrote that has thousands of downstream dependents.
After agreeing on the river analogy, the group then brainstormed and categorized ideas for good author practices for “way upstream”, “way downstream”, and “in the middle”. I’ll be writing those up in detail in my summary of the Berlin consensus discussions.
Finally, we spent some time talking about what to do when an upstream distribution isn’t being managed with the standards of care that one would like. The group agreed that if an upstream author isn’t responsive to one’s concerns, then forking (same code/API) or replacing (new code, maybe new API) are the only real options. We talked about how to do that respectfully to the upstream author and responsibly to the community. I’ll be writing up those guidelines later as well.
Rethinking Metabase 🔗︎
Back on Saturday, I’d revived Metabase::Web, so I started examining the MongoDB backend in more detail, to see if the choices I made years ago still made sense. Unfortunately, the more I looked at how Metabase organizes information, the more I saw how terribly convoluted it is. It’s got second-system problems all over.
I think I’ve learned a lot since coming up with it 7 or 8 years ago, so rather than blindly pushing forward with a migration, I decided to start thinking about a plan for CPAN Testers 3.0 instead. (It will be done by Christmas.)
Test::Reporter::Transport::MongoDB 🔗︎
Before designing CPAN Testers 3.0, though, I needed to consider how to regression test Test-Simple and its 6000+ selected dependents (still a subset from the entirety of CPAN that depends on it).
In the past, when regression testing Module::Build, I use CPAN Testers smoking tools, but saved reports as files. One directory had reports with the stable version installed and another had reports with the development version installed and I compard the differences.
Given the scale of testing, and DreamHost’s generous donation of testing machines, I wanted to explore distributing the testing jobs and collecting the results back rather that shuttling report files around multiple machines.
To that end, I wrote and tested a rough draft of Test::Reporter::Transport::MongoDB to send a smoke test report directly to a MongoDB server. That will let me collect the distributed regression test reports and meanwhile experiment with how best to organize report data as the basis for CPAN Testers 3.0.
Fixing Capture::Tiny 🔗︎
For quite a while, Capture::Tiny has been failing tests with bleadperl on Windows due to problems closing a bad file descriptor. I hadn’t been able to figure out why, but at the hackathon, Bulk88 got out his C debugger and dug into the problem, identifying that the underlying issue had been there for years, but that the new automatic-close error warnings in blead made it visible.
With that little hint, I quickly tracked down the problem to an unnecessary Windows-level OS handle close. I can’t even remember why that I thought it was necessary, but changing it to an ordinary Perl close solved the problem. Bulk88 verified the fix and I shipped a trial to CPAN.
UTF-8 YAML::XS API 🔗︎
This year, Ingy was at the hackathon working on the YAML ecosystem. A big sticking point to unifying YAML implementations is the different expectations for the input to the Load function. YAML and YAML::Tiny expect it to be a character string, but YAML::XS expects it to be a UTF-8 encoded string.
We discussed whether it’s possible for the XS Load to detect whether it’s being passed character data or UTF-8 encoded data and, in short, it’s not possible to do so unambiguously for all all input.
PAUSE on Plack! 🔗︎

I had nothing to do with this — it was all Kenichi Ishigaki! But it was the awesomest hack of the hackathon, in my opinion, so I wanted to mention it. The picture above shows Andreas and Kenichi with their PAUSEs running side-by-side.
Class::Tiny custom accessors 🔗︎
As part of his work hacking on CPAN::Common::Index, Miyagawa found some surprising behavior in the use of custom accessors. It was a great point and I need to think about whether to do something about it or just better document it to be less surprising to others.
Hash::Ordered pull requests 🔗︎
In the past month, I’d received a couple pull requests for Hash::Ordered so I tested them, applied them, and shipped a Hash::Ordered dev release.
Day 5 🔗︎
Monday was travel day. I spent much of the flight working to wrap things up. Using notes from Wendy, I typed up an outline of all the consensus discussions. I also worked on optimizing my META file scanner, getting it down from 40 minutes to about 10! I also scripted my Test::Builder dependency analysis so it would be repeatable as I continued to refine my META analyzer.
Parting thoughts 🔗︎
As in the past, I finished this hackathon feeling a bit wrung out, but excited and proud of everything that got done.
The CPAN ecosystem is not just libraries of code and tools; it’s a community of people.
This year in particular, I think the “consensus discussions” have a chance to positively influence people far outside the QA/Toolchain bubble.
For more on the hackathon, check out the hackathon’s blogs and results pages.
Thanking those who made it possible 🔗︎
As an invitational-event, the hackathon wouldn’t be possible without the sponsors who provide the funds to bring so many people together.
It’s not too late to donate! Any support in excess of this year’s budget will be banked for the 2016 hackathon, so if you’re feeling inspired, please give back or encourage your employer to do so.
This year, I particularly want to thank my employer, MongoDB, for sponsoring me to attend.
Our other wonderful corporate sponsors include thinkproject!, amazon Development Center, STRATO AG, Booking.com, AffinityLive, Travis CI, Bluehost, GFU Cyrus AG, Evozon, infinity interactive, Neo4j, Frankfurt Perl Mongers, Perl 6 Community, Les Mongueurs de Perl, YAPC Europe Foundation, Perl Weekly, elasticsearch, LiquidWeb, DreamHost, qp procura, and Campus Explorer. These companies support Perl and I encourage you to support them.
We also had several generous individual contributors, who also deserve our thanks: Ron Savage, Christopher Tijerina, Andrew Solomon, Jens Gassmann, Marc Allen, and Michael LaGrasta.
I particularly want to thank our organizer, Tina Müller, and the others who helped her plan and run an excellent event!
I also want to acknowledge Wendy van Dijk, who was my scribe for the hours of group discussions I moderated. Having her capture the discussions and transcribe the notes was an enormous help and I wouldn’t want to have led those discussions without her backing me up. Thank you, Wendy!